OrientationObservationIn-depth interviewsDocument analysis and semiologyConversation and discourse analysisSecondary Data
SurveysExperimentsEthicsResearch outcomes
Conclusion
8.4.3.5.1 Introduction
A hypothesis test is a statistical test that determines whether the data derived from a sample is sufficient to make claims about the population from which the sample was drawn.
A hypothesis test is based on probability theory and works by comparing two alternative hypotheses. Essentially, the process involves stating a 'no effect' or 'no difference' hypothesis (called a null hypothesis) and seeing whether the sample data is able, at a stated level of probability, to reject this null hypothesis. This Section explores the process of hypothesis testing in some detail.
The analysis section explains how to derive the confidence interval (Section 8.4.3.3) around a population mean or proportion on the assumption that the distribution of sample means approximates a normal distribution.
Note: when a sample of a given size is taken from a population, it is one of all the possible samples of that size. Each of these possible samples will have a mean. Some sample means will be larger than the population mean (where the sample, at random, selects more large values than small) and some will be smaller (where the sample, at random, selects more small values than large). These different means form a (theoretical) distribution, known as the sampling distribution (or distribution of sample means). Most of the sample means will be fairly close to the actual population mean and a few being further away: this approximates what is called a normal distribution. The avergae value of all the possible sample means will be the same as the population mean.
The confidence interval gives the limits within which we expect to find the population parameter with a given probability (the confidence level).
Having defined this interval, how can we make use of it? One of the fundamental uses of confidence intervals is to see whether a claimed value of a population is or is not a possibility.
Suppose a claim is made as to the value of a population mean. This could be checked by measuring the entire population but it is usually impractical to collect the relevant data of every member of the population and so a (representative) sample is taken. The sample mean is calculated and this gives the best unbiased estimate of the population mean.
The claimed population mean is then compared with the sample mean to see if the claim is possible or not. However, it is not sufficient merely to see to whether the claimed mean and the sample mean coincide and then reject the claim if they do not.
Why? Because the sample mean does not necessarily equal the population mean. However, we are 95% sure that the true population mean will lie within the 95% confidence limits derived from an unbiased sample and therefore if the claimed value of the mean does not lie within the confidence limits we can be 95% sure that the claimed mean is not the same as the population mean.
Similarly, if we compute the 99% limits and see that the claimed population mean does not lie within the interval we can be 99% sure that the claimed value of the population mean is different from the true value of the mean.
Thus, it is possible to see if a claimed value of a population mean is likely to be false by computing the confidence interval on the basis of the sample data and then rejecting the claim if the claimed value of the population mean lies outside the confidence limits of the true population mean.
This procedure is the basis for hypothesis testing in general. In the comments above and in the subsequent development of the concept of hypothesis testing, we test the hypothesis that the claimed value of the population mean is equal to the true population mean. In shorthand the hypothesis we are testing is that:
Hypothesis: Population mean (µ) = hypothesised population mean (µ0)
where µ is the true value of the population mean
and µ0 is the hypothesised (or claimed) value of the population mean.
8.4.3.5.2 The null hypothesis
The hypothesis we are testing is called the null hypothesis and is represented by the convenient shorthand H0.
Note the subscript '0': in sampling theory, wherever a parameter has a '0' subscript it means that the parameter has the value attributed it by the null hypothesis.
Consequently the shorthand for 'we are testing the hypothesis that the claimed value of the population mean is the same as the true value of the population mean' is:
H0: µ0=µ
This is one of many possible null hypotheses.
Another one is:
H0: ∏0=∏
(i.e. the assumed value of the population proportion (∏) is tested to see whether it equals the actual value of the population proportion).
8.4.3.5.3 The alternative hypothesis
Having specified the null hypothesis that is to be tested we must also state the hypothesis we will accept if we reject the null hypothesis. The hypothesis that we are testing the null hypothesis against is known as the alternative hypothesis and is represented by HA.
8.4.3.5.4 Example of hypothesis testing (H0: µ0=µ) by calculating confidence intervals
Let us consider an example to illustrate what has been covered so far in this section. A firm claims that it has produced a machine for making bars of soap and that it will output 1000 bars an hour. A soap manufacturer installs one of the machines and discovers that on average over a working week of 50 hours the machine only produces 970 bars per hour with a standard deviation of 91 bars. Is there a significant difference between the claimed output and actual output of the machine?
Superficially, we could say that there is a difference between the actual and claimed output, because the sample mean is not as large as the claimed mean. However, such a hasty decision is problematic because the sample is prone to sampling error. How do we eliminate the effects of sampling error? By calculating the confidence interval for the mean of the population on the basis of the sample data. What we need to compare is the claimed and true population means. However, the actual population mean is unknown and must therefore be estimated from the sample data by calculating the confidence limits.
We are, therefore, testing the hypothesis that the true population mean is the same as the claimed population mean:
H0: µ0=µ
Against the alternative hypothesis that they are not the same:
HA: µ0≠µ
Let's test at a 95% level of confidence. Now we calculate the confidence limits, not forgetting that if the value µ0 lies outside the limits we reject H0 in favour of HA.
The 95% confidence limits are:
Sample mean – z(standard error) ≤ population mean ≤ sample mean + z(standard error)
Sample mean = 970 Sample standard deviation = 91
z= 1.96
Standard error = sample standard deviation/√(n-1) = 91/√(50-1) = 91/√49 =91/7 =13
(The divisor n-1 is used rather than n, as dividing by n gives a biased estimate of the population mean, see CASE STUDY Standard error).
Consequently we are 95% sure the population mean (µ) lies with the range 944.52 and 995.48. The hypothesised value of the mean (µ0) is 1000 and is not within that range. Therefore the true population mean (µ) is different from the claimed value (µ0). Therefore, we reject the null hypothesis at a 95% level of confidence. We can say that the machine maker's claim is significantly different from that found in practice.
When we say a population mean is significantly different from a hypothesised value of the population mean, this indicates that, the sample mean, which is the estimate of the population mean, differs from the assumed value of the population mean by a margin greater than that which could be accounted for on the basis of random sampling error.
Hypothesis testing is the name given to the statistical analysis that attempts to see whether the discrepancy between the assumed and actual parameter is significant.
8.4.3.5.5 Deciding on the confidence level
In the calculation of the example in Section 8.4.3.5.4 we rejected the null hypothesis at a 95% level of confidence. This means that we are 95% certain that the claim is unjustified. Which implies we are 5% unsure! In effect we are running a 5% risk of wrongly rejecting the null hypothesis, (which is called a Type 1 error).
In a lot of circumstances we would be prepared to accept a 5% risk of wrongly rejecting are null hypothesis. However, it is possible that we would prefer a reduced risk. One way of reducing the risk is to increase the confidence interval.
For example, if we calculate the 99% confidence interval we are 99% sure that the population mean lies within the range and the risk that it does not is only 1%. Therefore, if the hypothesised value of the mean lies outside the confidence limits then there is only a 1% chance that the population mean is the same as the hypothesised mean and we only run a 1% risk of wrongly rejecting the null hypothesis. However, by increasing the confidence interval we do lose precision in our estimate of the population mean.
Let's calculate the 99% confidence interval for our example in Section 8.4.3.5.4. The only change is that z equals 2.58.
We can now see that with a wider interval and a higher level of confidence, the hypothesised value of the mean (i.e. 1000) is included in the interval and we cannot reject H0.
In deciding upon the confidence interval we face a dilemma. Do we reduce the risk of wrongly rejecting the null hypothesis or do we retain the precision of the estimate of the population mean? The answer depends upon how important it is not to make a mistake in rejecting the null hypothesis. This 'importance' is frequently a matter of personal choice. If a legal decision is going to be based upon the findings, or if it is the case of 'life and death' then it is normal to use a high level of confidence (99% or more), otherwise 95% level is usually sufficient for social, business and economic research situations.
One cannot be categorical about the confidence level to be used, it is up to the tester to decide. By convention the choice is usually between using a 95% level or 99% level. The choice of one or the other will only affect the decision when the hypothesised value falls between the 95% and 99% confidence limits. When we reject at a 99% level we will also reject that a 95% and if we cannot reject at 95% we cannot reject at 99%.
8.4.3.5.6 Rejecting or not rejecting the null hypothesis
In the preceding examples (Sections 8.4.3.5.4 and 8.4.3.5.5) we 'rejected the null hypothesis' or 'did not reject the null hypothesis'; nowhere in the preceding discussion have we ever accepted a null hypothesis. In fact, we rarely set up a hypothesis test to accept the null hypothesis. If the value of the hypothesised mean (µ0) falls within the confidence limits, all this allows us to say is that the null hypothesis is a possibility that cannot be rejected. However, just because it falls within the limits does not prove that the hypothesised value of the mean is true. It is merely a possibility; the hypothesised value would then be one of many values in the confidence limits.
Only when the hypothesised value is outside the limits is it possible to be categorical (at a given degree of confidence) and say that the null hypothesis can be rejected.
8.4.3.5.7 Testing H0: ∏0 = ∏ by calculating confidence intervals Section 8.4.3.5.4 illustrated a test of a claimed population mean. The following illustrates a test of a claimed population proportion.
Suppose a claim is made that 80% of grammar school children in the United Kingdom are middle class. Taking a random sample and calculating the confidence limits we could see whether this claim is true or not. We take a sample because it would be prohibitively expensive to investigate the social class of every grammar school child in the country. Once the criteria for 'middle class' has been established a random sample is selected by some mechanism (see Section 8.3.9 on sampling). A random sample of 1000 grammar school students comprised 750 middle class (= 0.75) and 250 non-middle-class (= 0.25).
The sample proportion (p) of 0.75 is below the claimed population proportion (∏) of 0.8 (80%) but is this just due to sampling error?
We can test to see whether the difference between the sample proportion and the population proportion is due to sampling error or whether it is statistically significant. We are thus testing the claim that the population proportion is 0.8 eight against the alternative that it is not 0.8:
H0: ∏0 = ∏ = 0.8
HA: ∏0 ≠ ∏ ≠ 0.8
The basis for the test is a sample with p=0.75. Calculating confidence interval around p gives the range within which the population proportion will lie (to a given degree of confidence). Since the sample size is greater than 30 and hence the binomial distribution approximates the normal distribution we can use normal curve analysis to derive the confidence interval.
If the interval is not wide enough to embrace the hypothesised value of the population proportion we reject the null hypothesis.
Calculation of the confidence interval for our sample at a 95% level:
p – z(standard error of p) ≤ ∏ ≤ p + z(standard error of p)
where ∏ is the population proportion
The standard error of p is calculated using the claimed value of the population proportion because that is the value we are testing. We are testing on the basis of the sampling distribution that assumes that the value ∏0 is in fact the mean of the distribution. So the formula for the standard error of proportion in this case is:
√∏0(1- ∏)/n = √0.8(0.2)/1000 =√0.00016 = 0.012649
The 95% confidence limits around the sample proportion are thus:
Therefore the population proportion (∏) is between 72.52% and 77.48% and we can reject the null hypotheses, which maintains that 80% of grammar school children are middle-class, at a 95% level of confidence.
Had we used the sample proportion (0.75) to compute the standard error of proportions the confidence limits would have been 0.7290 ≤ π ≤ 0.7704, which also leads to a rejection of the null hypothesis.
8.4.3.5.8 Testing hypotheses by computing a z value (on the basis of the assumed population parameter)
Another way of testing a hypothesis is to compute the difference between the sample parameter and the hypothesised population parameter and divide it by the standard error and see if it is larger or smaller than the appropriate z value (1.96 for 95% confidence level or 2.58 for a 99% confidence level).
z is greater than 2.58 and so the null hypothesis is rejected at 99% confidence level
or put another way the probability of the population proportion being 0.8 in this case is less than 1%.
In fact, the exact probability can be looked up in normal distribution tables or would be provided by a computer program.
8.4.3.5.9 Testing statistic
In the above example the statistic we are basing our test decision upon is 'z'. In this case z is the testing statistic. The testing statistics will not always be z; it depends on the characteristics of the sample and the comparisons being made. It applies in the examples we have looked at so far because it is assumed that the sampling distribution is normal.
(Note the sampling distribution we have looked at have been either distributions of sample means or distributions of sample proportions and these are approximately normally distributed when the sample size exceeds 30).
When we use a z testing statistic to test a hypothesis we usually refer to our test as a z-test. Frequently hypotheses tests are named after the statistic used to test them, for example, F test, t-test, U-test and so on.
8.4.3.5.10 Critical value
The calculated value of the testing statistics (from the sample data) is compare to the value that pertains for any given confidence level, (see Section 8.4.3.5.8). This value of the testing statistic is known as the critical value.
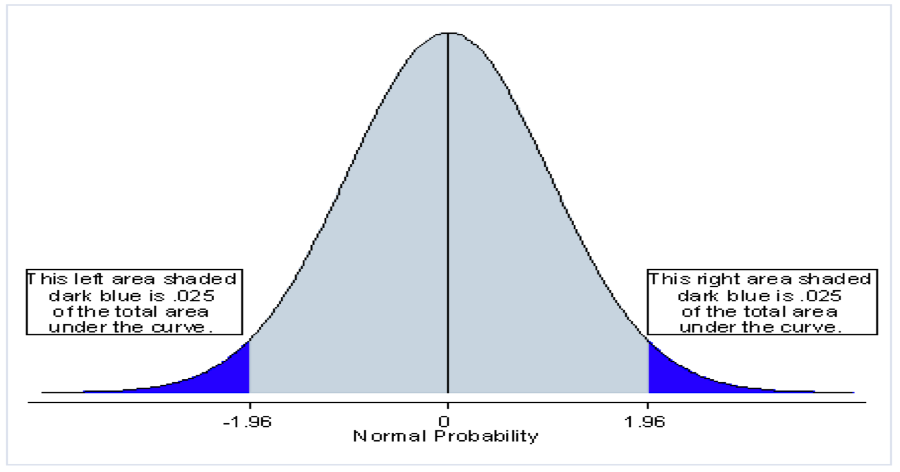
For example, for z-tests, the critical z value that corresponds to the 95% confidence level is 1.96 (for a two-tail test see Section 8.4.3.5.13) because 95% of the area under the normal curve lies within 1.96 standard units either side of the mean of the distribution.
If the calculated value is greater than the critical value the null hypothesis is rejected; this is then our decision rule.
8.4.3.5.11 Layout for testing hypotheses
Let's reconsider the steps we take when testing a hypothesis.
First, define the null hypothesis and the alternative hypothesis.
Second, state the level of confidence for the test.
Third, choose an appropriate testing statistic, which will depend on the null hypothesis and the sample data.
Fourth, derive the critical value of the testing statistic, which depends upon the hypotheses and the level of confidence.
Fifth, state the basis for rejecting, or not rejecting, the null hypothesis. This is the decision rule (based on the hypotheses, confidence limit and testing statistic).
Sixth, compute the testing statistic.
Seventh, compare the computed and critical value of the testing statistic and, on the basis of the decision rule, draw some conclusions relating to the null hypothesis.
8.4.3.5.12 Example of testing hypotheses of the type H0: µ0=µ
A company sells its products via door-to-door commissioned salesmen and women. The firm decides to increase prices and consequently the sales personnel earn more commission on the same number of sales. However, as there are other firms of a similar nature, the increasing prices causes the number of sales per agent to decline. The commission earned in the past by all sales personnel was £1500 per month. The firm is concerned that the commission earned by sales personnel has changed so it takes a random sample of 101 returns from the commission accounts and find the sample mean is £1450 with the standard deviation of £50. Has the average commission earned changed?
1. Hypotheses:
H0: µ0 = µ = £1500 HA: µ0 ≠ µ ≠ £1500
The null hypothesis is that there has been no change in the mean commission earned, i.e., that the mean of the population from which the sample has been taken is equal to the hypothesised value of the population mean (µ0), which in this case is equal to the average earned before the firm increase prices.
2. Level of confidence: 95%
3. Testing statistic:
z = (sample mean - π0)/standard error of means
We are testing the population mean, the sample size is large, therefore we may assume the distribution of sample means is normal, hence we use a z-test.
4. Critical value: z = ± 1.96
95% of the area under the normal curve lies between ±1.96 standard units from the
mean.
5. Decision rule: reject the null hypothesis if z < –1.96 or z > 1.96 (i.e., absolute value of z exceeds 1.96). Note that z could be a negative number if the sample mean is less than the hypothesised value of the population mean.
6. Computations:
Standard error of the mean = sample standard deviation/√(sample size-1)= 50/√(101-1)
Standard error of the mean = 50/√100 = 50/10 = 5
z= (sample mean - population mean)/standard error of means
z= (1450 – 1500)/5
z= –50/5 = –10
7. Decision: reject the null hypothesis as the calculated z value exceeds the critical value of 1.96; therefore the commission earned by a sales person has changed significantly at the 95% level of confidence.
8.4.3.5.13 One- or two-tailed tests
In all the examples so far alternative hypothesis has been either HA: µ0 ≠ µor HA: π0 ≠ π .
However, there are other possible alternative null hypothesis. For example:
µ0> µ µ0< µ.
How is the test affected by defining an alternative that specifies the direction of the change (i.e., the population mean is less than the claimed mean, or the population meaning is greater than the claimed mean) rather than an alternative that simply specifies that the changes occurred without indicating whether it is up or down?
When testing H0: µ0 = µ against HA: µ0 ≠ µ at 95% confidence interval the critical value of z is found by ascertaining the number of standard units either side of the mean of the normal curve, which contains 95% of the area under the curve; i.e., 47.5% of the area on each side of the mean, hence the area under the curve outside the confidence limits is equal to 2.5 on each tail. When testing for a change in µ without specifying any direction this is a two-tailed test and the significance level is split equally between the two tails of the distribution (see Figure 8.3.13.13.1).
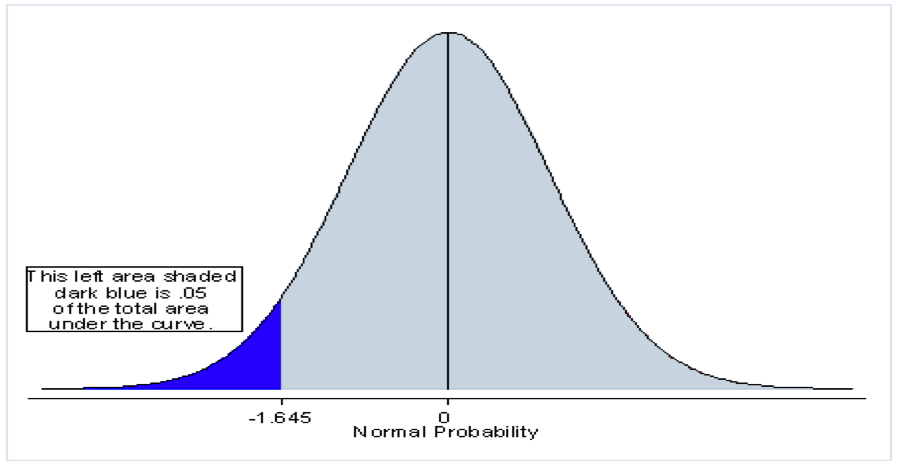
If the alternative hypothesis is µ < µ0, then the direction of the change has been defined and we are concerned only with the lower tail of the sampling distribution, the upper limit is of no interest. The null hypothesis can only be rejected if the population mean falls into the lower tail of the distribution and so at a 95% level of confidence all of the 5% rejection region would be at the lower end (see Figure 8.3.13.13.2).
This impacts on the value of critical value of z. The decision rule becomes unidirectional, so that, in this case, we would only be interested in negative z scores. The corollary is that the z value would be lower because there are fewer standard units between the mean and the area containing 5% of the curve to the left than between the mean and 2.5% to the left. In this case the critical value of z = 1.645.
Useful critical values of z:
Level of confidence
95%
99%
One tail test*
1.645
2.33
Two tail test
±1.96
±2.58
* plus or minus depending on the direction of the test.
8.4.3.5.14 Summary of hypothesis testing
The general principles for hypothesis testing are:
1. Define the hypotheses: null hypothesis (H0) and alternative hypothesis (HA).
2. Decide upon an appropriate confidence level; usually 95% or 99%.
3. Derive the testing statistic, this is the basis for the computation and decision regarding the null hypothesis (H0) and depends upon the test used.
4.Derive the critical value for the testing statistic this depends upon the hypotheses and the confidence level.
5. State the decision rule, always of the form 'reject the null hypothesis (H0) if ' the critical value is not satisfied.
6. Calculate the testing statistics on the basis of the sample data.
7. Decision: by comparing the calculated and critical value of the testing statistic on the basis of the stated decision rule, the null hypothesis is either rejected or not rejected at a given level of confidence (significance). Finally, explain what the decision means in relation to the data being tested.
Note that there is always a small possibility that the decision is incorrect. There are two types of errors that can result from a hypothesis test. These are known as Type I and Type II errors.
A Type I error occurs when the researcher rejects a null hypothesis when it should not have been rejected. The probability of committing a Type I error is the significance level (usually 5% or 1%). This probability is also referred to as 'alpha'.
A Type II error occurs when the researcher fails to reject a null hypothesis that is false. The probability of committing a Type II error is called 'beta'. A Type II error occurs when the test is not sufficiently sensitive or powerful enough to identify a difference when it actually exists. This may be, for example, because the sample is not big enough, the confidence level is set too high or the measured difference is small. The probability of not committing a Type II error is called the 'power' of the test.
The consequences of a Type I and a Type II error are not the same. Suppose two alternative headache pills are being compared to see which acts faster. Rejecting a null hypotheses that says that they act equally fast (H0:µ1=µ2) is a Type I error when in fact they are equally speedy. The consequence of wrongly rejecting the null hypothesis is not problematic as the benefit to patients is the same for either pill. However, a Type 2 error, failing to reject the null hypothesis when it should be rejected, means that the faster acting pill is not made available in preference to the slower acting one. So, when conducting a hypothesis test, consider the consequences of making Type I and Type II errors and choose the testing circumstances that take account of the consequences.
Activity 8.4.3.5.1
If you want to understand the principles of significance testing make sure you are able answer the following.
What is a sample?
What is the population?
What is sampling error?
What causes sampling error?
What is standard error?
What is a sampling distribution?
How does the sampling distribution differ from the population distribution?
What are confidence limits?
What is meant by significance level?
What is the null hypothesis?
Why do we define an alternative hypothesis?
What does the critical value of the testing statistics show?
What defines the testing statistic?
What is the basis for the decision rule when testing a hypothesis?
Why do we never accept the null hypothesis?
In the end, the analysis is guided by the hypotheses (see Section 8.3.4) being explored and relies on the ingenuity and imagination of the researcher in relating the data to social scientific theory.